Apa itu Web Crawler?
Web crawler adalah bots yang bekerja merayapi/menelusuri seluruh World Wide Web, melakukan crawling data, dan mengindeks-nya.
Crawling data adalah metode pengumpulan data dengan menelusuri suatu web melalui setiap link yang ada di dalamnya.
Indexing adalah proses mengumpulkan setiap halaman web berdasarkan kategori tertentu, kemudian mengkatalogisasi semua di data center.

Search engine atau mesin pencari secara umum menggunakan bots ini untuk menjalankan fungsi pencarian.
Mesin pencari menerapkan algoritma penelusuran ke data yang dikumpulkan crawler atau perayap web. Dengan demikian, mesin pencari bisa memberikan rekomendasi halaman yang relevan di hasil pencarian (SERP).
Setiap mesin pencari memiliki bots masing-masing. Misalnya, Google yang memiliki Googlebot, Slurp Bot milik Yahoo, Bingbot dari Bing, DuckDuckBot milik DuckDuckGO, dll.
Jika Anda pernah bertanya-tanya, bagaimana mesin pencari bisa memberi jawaban untuk setiap keyword yang kita input, itu karena kinerja bots ini.
Cara Kerja Web Crawler
Proses crawling bermula dari seed, atau daftar URL yang sudah diketahui crawler. Ia akan merayapi laman web dari daftar URL tersebut.
Pada proses tersebut, biasanya bots akan menemukan link ke URL lain. Hal itu akan masuk ke list halaman untuk dirayapi setelah proses sebelumnya selesai.

Proses ini berlangsung secara berulang dan terus menerus hingga tanpa batas. Pasalnya, saat ini sudah ada sangat banyak halaman web di internet.
Setiap search engine menerapkan algoritma tertentu. Kemudian, bots atau crawler akan bekerja berdasarkan ketentuan yang tertulis di algoritma.
Setidaknya ada tiga prinsip yang jadi acuan kerjanya.
➜ Mengutamakan Web Page yang Valuable
Di antara begitu banyaknya halaman web di internet, tidak semuanya penting. Pasti ada saja web yang berisi informasi yang tidak terlalu berguna untuk user.
Maka dari itu, bots akan mengutamakan halaman yang penting (valuable).
Hal yang jadi acuan untuk menilai seberapa penting suatu halaman yaitu kualitas backlink, jumlah pengunjung, dan faktor-faktor lain.
Kemungkinan besar, web page yang jadi rujukan dari banyak web lain dan memiliki banyak pengunjung akan berisi informasi otoritatif berkualitas tinggi.
Anda sebagai user tentu lebih puas jika rekomendasi dari mesin pencari berisi informasi yang akurat dan berkualitas. Maka dari itu, bots mesin pencari akan mengutamakan halaman semacam ini demi menunjang kepuasan user.
➜ Mengunjungi Ulang Web Page untuk Memeriksa Update
Rata-rata, setiap web pasti mengalami pembaruan secara berkala. Kecuali pemiliknya lupa akses ke website tersebut sehingga tidak bisa melakukan update.
Nah, crawler akan melakukan kunjungan ulang ke setiap web page yang sudah pernah terindeks untuk memastikan versi teranyarnya.
Untuk jangka waktunya, tergantung kebijakan dari masing-masing mesin pencari.
➜ Mengikuti Protokol Robot.txt
Robot.txt pada dasarnya adalah suatu file teks berisi aturan tertentu mengenai akses bot pada suatu web. Jadi, file ini akan jadi panduan untuk bot merayapi halaman mana dan mengikuti tautan yang mana.
File robot.txt ini bisa Anda buat sendiri. Anda bisa membuat script-nya secara manual dengan text editor. Jika Anda menggunakan WordPress, ada sejumlah plugin yang bisa membantu Anda mengelola hal ini.
Setiap search engine memiliki algoritmanya masing-masing. Maka dari itu, bot atau crawler-nya memiliki perilaku yang berbeda-beda pula.
Para praktisi SEO akan mempelajari hal tersebut dan merumuskan teknik-teknik yang bisa diaplikasikan untuk mengoptimasi halaman web di mesin pencari.
Sebagai pemilik web, Anda harus memastikan bahwa website Anda sudah terindeks mesin pencari. Pasalnya, jika belum terindeks, website Anda tidak akan muncul di hasil pencarian.
Beberapa cara yang bisa Anda tempuh yaitu: registrasi website di Google Search Console, membuat sitemap XML, dll.
Fungsi Web Crawler
Pada prinsipnya, web crawler berfungsi untuk merayapi dan mengindeks seluruh halaman atau konten yang ada di internet.
Bisa diambil kesimpulan, crawler adalah pondasi atau dasar dari fungsionalitas mesin pencari.
Di samping itu, web crawler juga memiliki banyak fungsi lainnya. Tidak hanya mesin pencari, bot semacam ini juga digunakan oleh perusahaan yang berbasis di bidang data.
Apalagi saat ini sudah ada banyak web crawler tool yang bisa Anda manfaatkan untuk mengumpulkan data tertentu dari internet.
Nah, secara lebih luas, manfaat crawler adalah sebagai berikut:
1. Melihat Data Perbandingan Harga
Di internet ini ada banyak sekali toko online. Harga suatu produk di tiap toko online bisa jadi berbeda-beda.
Crawler bisa melakukan perbandingan harga terhadap suatu produk di internet.
Dengan tool semacam ini, Anda bisa melihat perbandingan harga produk tanpa harus mengecek secara manual ke tiap-tiap toko online.
Google Search Console adalah salah satu web analysis tool milik Google. Tools ini bisa membantu Anda menganalisis suatu web untuk mengetahui page view, backlink, internal link, dll.
Tool ini menggunakan crawler untuk mengumpulkan data-data tersebut.
Data mining merupakan suatu proses untuk menemukan pattern tertentu dari set data yang besar dengan melibatkan teknik machine learning, statistik dan database system.
Dalam konteks ini, crawler bertugas mengumpulkan set data dari sumber terbuka di internet. Misalnya, alamat email atau nomor telepon sejumlah perusahaan yang terbuka untuk umum.
Web Crawler: Bot Mesin Pencari Untuk Mengindeks Web Page
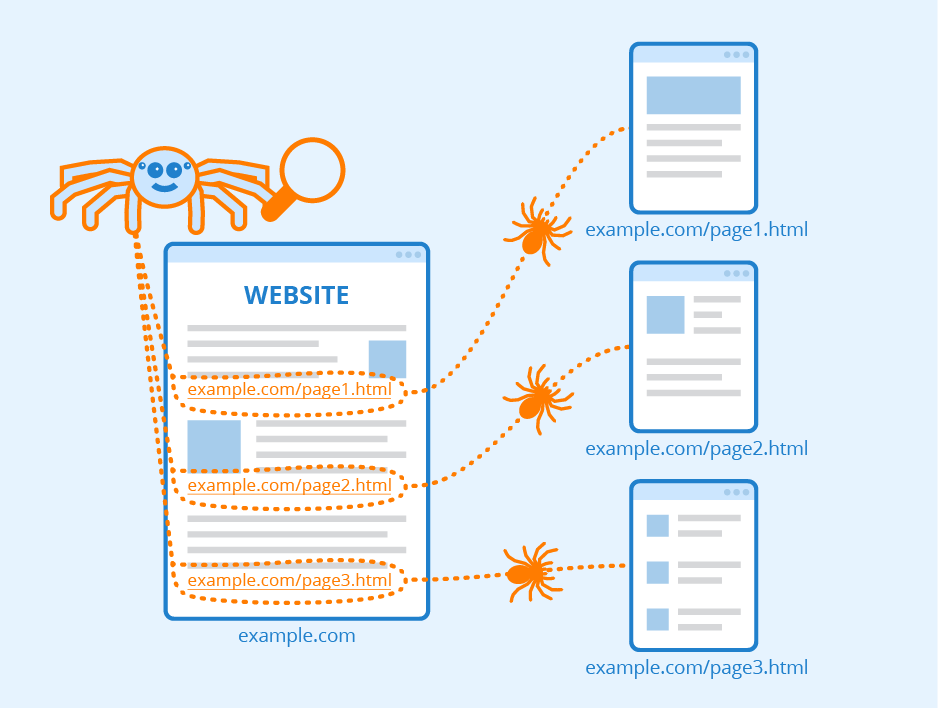
Setiap search engine memiliki web crawler/spider/bots untuk menunjang fungsionalitasnya. Program ini bertugas merayapi setiap halaman web dan melakukan indexing.
Bot melakukan indexing dengan menelusuri setiap link yang ada di halaman web. Proses ini akan berlangsung sampai tidak terhingga.
Setiap bot akan bekerja sesuai algoritma yang diterapkan oleh platform yang menaunginya. Misalnya Googlebot, kinerjanya akan mengikuti algoritma Google.
Program ini tidak hanya menunjang fungsi mesin pencari. Dalam ekosistem big data, program ini juga dimanfaatkan terutama untuk collecting data.